
AMD در رویداد Next Horizon که در جریان E3 سال جاری برگزار شد، اطلاعات خوبی در مورد پردازندههای گرافیکی Navi با معماری جدید RDNA ارائه داد. این پردازندهی گرافیکی قرار است در دو مدل کارت گرافیکRadeon RX 5700 XT و Radeon RX 5700 مورد استفاده قرار گیرد. AMD قصد دارد این دو کارت گرافیک را به میدان رقابت با کارتهای تورینگ RTX 2070 و RTX 2060 انویدیا بفرستد.

AMD در اولین موج پردازندههای گرافیکی Navi (با عنوان Navi 10) از قابلیت رهگیری پرتو (Ray Tracing) مبتنی بر سختافزار استفاده نخواهد کرد. دیوید وانگ که در راس RTG (گروه فناوریهای رادئون) قرار دارد بر این باور است که در حال حاضر محاسبات رهگیری پرتو در فضای ابری (کلاود) به بهترین نحو انجامپذیر است و پس از آن میتوان نتایج محاسبات را به خروجی نمایشگرها ارسال کرد. باوجود چنین رویکردی ممکن است AMD پردازندههای گرافیکی Navi 20 را که تا سال ۲۰۲۱ عرضه خواهد شد، به این قابلیت مجهز سازد.
پردازندهی گرافیکی Navi که قدرت پردازش گرافیکی کارتهای سری RX 5700 را تأمین میکند، با فناوری ساخت ۷ نانومتری شرکت تایوانی TSMC تولید شده و مانند پردازندههای نسل سوم رایزن از استاندارد ارتباطی PCIe 4.0پشتیبانی میکند. بنابراین کارتهای گرافیک سری RX 5700 شرکت AMD اولین سری کارتهای گرافیکی خواهد بود که با نصب روی اسلات توسعهی نسل چهارم PCIe از تمام ظرفیت پهنای باند آن به خوبی پشتیبانی خواهد کرد. پردازندهی گرافیکی Navi با بهرهمندی از موتورهای Radeon Media و Radeon Display تمامی نیازهای استریمرها و تولیدکنندگان محتوا را به خوبی برآورده ساخته و آنان را به سمت مجموعهای از تکنولوژیهای جدید نمایشگر رهنمون میسازد.
پردازندههای گرافیکی Navi اگرچه میراثدار معماری استقرار یافتهی GCN هستند، بهلطف معماری جدید RDNA بهبودها و تحولات زیادی را تجربه کردهاند. به عبارت دیگر Navi را میتوان عصارهی دو معماری GCN و RDNA دانست. AMD بهخوبی میداند که GCN همچنان راه حلی بسیار خوب برای اجرای وظایف محاسباتی سنگین است؛ وظایفی که در آن توان عملیاتی بالا و توازی کاری نقشی کلیدی ایفا میکند. پردازندهی گرافیکی Vega 64 با خصوصیات درخورتوجه خود در صدد غلبه بر کارت Geforce GTX 1080 بود، اما موفق به این کار نشد. علت ناکامی این کارت در غلبه بر پرچمدار رقیب این بود که تراشهی Vega که با معماری GCN تولید میشود، در به کارگیری زرادخانهی هستهها و حافظهی کش خود چندان مؤثر عمل نمیکند. در نقطهی مقابل پردازندههای گرافیکی Navi در این دو حوزه عملکرد بهتری دارند؛ چرا که بنا بهگفتهی AMD این تراشههای گرافیکی با ترکیب جدید و کاراتری از واحدهای محاسباتی (CU)، سلسله مراتب حافظهی کش و پایپلاینهای گرافیکی ارائه خواهد شد که در ادامهی این مقاله به بررسی این ویژگیها خواهیم پرداخت.
در اولین گام بهتر است نگاهی به دیاگرام بلوکبندی پردازندهی گرافیکی Navi 10 داشته باشیم. این پردازندهی گرافیکی در کارت گرافیک RX 5700 XT (با پیادهسازی کامل توان عملیاتی) و در کارت گرافیک RX 5700 (با توان عملیاتیِ کاهش یافته) بهکار رفته است.

پردازندهی گرافیکی Navi 10 دربرگیرندهی ۴۰ واحد محاسباتی (در قالب ۲۰ واحد دوگانه) است که هر واحد شامل ۶۴ پردازندهی جریانی یا شیدر است و در مجموع ۲۵۶۰ هستهی محاسباتی در قلب این پردازنده فعالیت میکند. درست است که تعداد این هستهها در مقایسه با تراشهی گرافیکی کارتهای Vega 64 و Vega 56 (با داشتن به ترتیب ۴۰۹۶ و ۳۵۸۴ پردازنده جریانی) کاهش یافته است، اما این بار با طراحی جدید و پر بازدهتری در هر CU با معماری RDNA روبهرو هستیم. هر CU در طراحی تراشهی Navi 10 شامل یک واحد اسکالر اضافی (که وظیفه آن اجرای محاسبات برداری ریاضی است) و یک زمانبند (scheduler) اضافی است که با ترکیب این دو نرخ اجرای دستورالعملها (Instruction Rate) نسبت به نسل قبل تا دو برابر افزایش مییابد. چنین ترکیبی برای اجرای بارهای کاری از نوع گیمینگ و پردازش محیطهای گرافیکی نسبت به GCN بسیار موثرتر عمل میکند.
در معماری جدید چیدمان SIMD-ها نیز دچار دگرگونی شگرف شده است. SIMD رشتهای از هستههای محاسبهگر منطقی (ALU) است که هر کدام از این هستهها یک آیتم کاری یا ترد از دستورالعمل صادرشده را در یک سیکل کلاک اجرا میکند. در معماری قدیمی GCN هر واحد محاسباتی دربرگیرندهی چهار SIMD16 (دارای ۱۶ هسته) و در معماری جدید RDNA هر CU دربردارندهی دو SIMD32 (دارای ۳۲ هسته) است. هر SIMD در معماری جدید RDNA یک واحد اسکالر و یک زمانبند مخصوص به خود دارد؛ این در حالی است که در طراحی GCN یک واحد اسکالر و یک زمانبند درمیان تمام SIMD-ها به اشتراک گذارده شده و این یکی از نقاط قوت معماری جدی به شمار میرود.
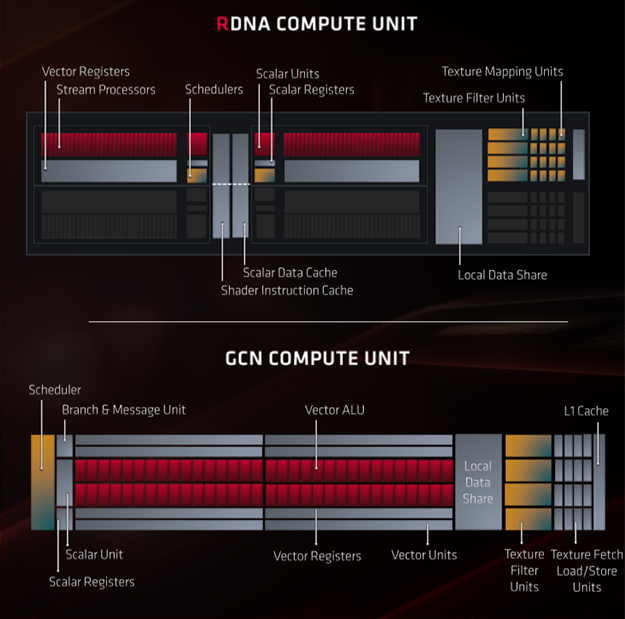
در معماری GCN هر دستورالعمل (در پیچیدهترین شرایط) بر جبههی موجی با ۶۴ ترد (Wave64) بار شده و برای اجرا به یک SIMD16 واگذار میشود. در این شرایط هر دستورالعمل در طی چهار سیکل کلاک میان ALU-ها توزیع شده، بهطور کامل اجرا میشود. بنابراین SIMD در معماری قدیمی قادر به پردازش یک دستورالعمل در یک سیکل کلاک واحد نیست. در این حالت در هر سیکل کلاک تنها از ۲۵ درصد ظرفیت هستههای منطقی موجود در هر واحد محاسباتی استفاده میشود و لذا میزان بهکارگیری (Utilisation) منابع چندان رضایت بخش نیست. در عوض در معماری جدید RDNA دستورالعملی با ۶۴ آیتم کاری بهصورت دو جبههی موج هر یک با ۳۲ ترد (Wave32) بهطور همزمان بین ۲ واحد SIMD32 توزیع میشود. در این حالت تمامی آیتمهای کاری در یک سیکل کلاک پردازش میشود. بدین ترتیب زمان انتظار برای دریافت نتایج پردازش کاهش یافته و از سویی ۱۰۰ درصد منابع واحد محاسباتی برای اجرای بهینهی تردهای پردازشی بهکارگیری میشود.

بهطور خلاصه میتوان گفت معماری RDNA، با سادهسازی دستورالعملهای صادر شده، به شیوهای تأثیرگذار از یک معماری متمرکز بر اجرای محاسبات سنگین، تبدیل به یک معماری سازگار با کدهای گیمینگ (Game-Freindly) میشود. محاسبات در این معماری خردتر شده و بهجای عرضهی دستورالعمل در جبهههای موج ۶۴ تایی، هر دستورالعمل بر یک جبههی ۳۲ تایی (یا در پیچیدهترین حالت بر دو جبههی ۳۲ تایی) بارگذاری شده و طی یک سیکل کلاک در SIMD32-ها اجرا میشود. کامپایلر در این معماری همچنان امکان انتخاب نوع دستورالعمل و شکل اجرای آن را دارد. این واحد میتواند دستورالعملها را بهصورت Wave32 فراخوانی کرده یا دستورالعملی بهصورت Wave64 را برای اجرا به دو SIMD32 موکول کند و انتخاب یکی از این دو شیوه بستگی به حجم پردازش و بار کاری پردازنده دارد.
در معماری جدید RDNA منابع پردازش دو واحد محاسباتی (CU) در مجاورت یکدیگر قرار گرفته و با بهرهگیری از توازی کاری مازاد، شیوهی عملکرد این دو واحد تطبیق و ترکیب پذیر بوده، امکان بارگذاری و اجرای گروههای کاری بزرگتری وجود داشته و درنهایت از میزان تأخیر کاسته میشود. بهطور کلی میتوان گفت که در معماری RDNA هدف اساسی کاهش تأخیر، بهبود عملکرد پردازش Single-Threading و بهینهسازی راندمان حافظهی کش در مقایسه با معماری GCN است. در معماری جدید در هر سیکل کلاک و در هر واحد محاسباتی میزان کار مفید بیشتری انجام میپذیرد.
شاید این سؤال پیش بیاید که با وجود دهها هزار ترد پردازشی در محاسبات گرافیکی، چرا تمرکز این معماری بر پردازش Single-Threading است. در پاسخ باید گفت که پر کردن واحدهای محاسباتی ماشینی با معماری GCN با طیف گستردهای از بارهای کاری متنوع و با وجود هزاران ترد منتظر پردازش کار آسانی نیست. به همین دلیل با تغییرات بارزی در معماری RDNA روبهرو هستیم که باعث میشود تمامی اجزای محاسبهگر ماشین همزمان با اجرای تردهای موازی درگیر شوند و این بهمعنای اجرای یک ترد توسط هر پردازندهی منطقی در یک سیکل کلاک (به عبارتی در واحد زمان) بدون معطل ماندن هیچ یک از هستهها است. با این فرض که دستورالعملهای صادر شده وابستگی زیادی به یکدیگر نداشته باشد و با داشتن ۲ واحد اسکالر و ۲ واحد زمانبند در هر CU و بازآرایی بهینهی واحدهای SIMD، به سطح عملکرد بالاتر و پایداری بیشتری در معماری RDNA دست خواهیم یافت.
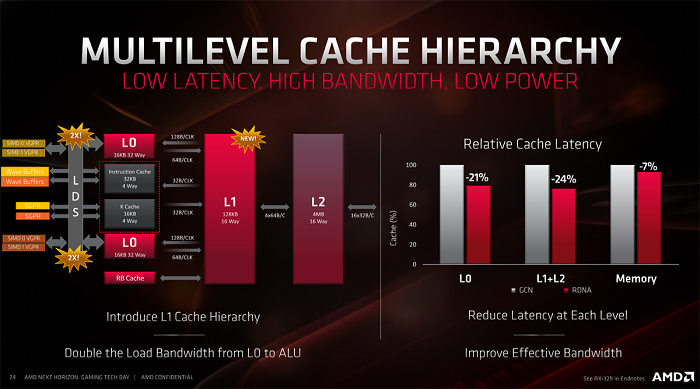
AMD در معماری گرافیکی جدید خود با الگوبرداری از پردازندههای نسل سوم رایزن، حافظه کش L1 اختصاصی را به تراشهی Navi اضافه کرده و پهنای باند بارگذاری را از نزدیکترین حافظهی کش (L0) به ALU دو برابر کرده است. در این جا هدف کاهش تأخیر در دسترسی به حافظهی کش در هر سطحی است. به عبارت دیگر در این معماری پهنای باند مؤثر افزایش مییابد؛ چرا که دادههای مورد نیاز بهجای آنکه از حافظههای فریم بافر کندتر واکشی شود، در سطوح مختلف کش پردازنده جایگذاری شده و از آنجا با سرعت بیشتری فراخوانی میشود.
 AMD تصریح کرده است که RDNA در سراسر پایپلاین از نظر فشردهسازی رنگ با بهبودهایی روبهرو است. در محیطهای گرافیکی دادههای گرافیکی از هر نوع و در هر محلی فشردهسازی میشود تا از میزان پهنای باند درگیر کاسته شود. معماری RDNA الگوریتم فشردهسازی رنگ دلتا (DCC) را بهبود بخشیده و اکنون شیدرها امکان خواندن و نوشتن مستقیم دادههای رنگ فشرده را دارند. بخش نمایشگر در این معماری قادر است بهصورت مستقیم دادههای فشردهی ذخیره شده روی سیستم حافظه را بخواند. در اینجا نیز هدف افزایش پهنای باند در دسترس و کاهش توان مصرفی نسبت به معماری نسل قبل GCN است.
AMD تصریح کرده است که RDNA در سراسر پایپلاین از نظر فشردهسازی رنگ با بهبودهایی روبهرو است. در محیطهای گرافیکی دادههای گرافیکی از هر نوع و در هر محلی فشردهسازی میشود تا از میزان پهنای باند درگیر کاسته شود. معماری RDNA الگوریتم فشردهسازی رنگ دلتا (DCC) را بهبود بخشیده و اکنون شیدرها امکان خواندن و نوشتن مستقیم دادههای رنگ فشرده را دارند. بخش نمایشگر در این معماری قادر است بهصورت مستقیم دادههای فشردهی ذخیره شده روی سیستم حافظه را بخواند. در اینجا نیز هدف افزایش پهنای باند در دسترس و کاهش توان مصرفی نسبت به معماری نسل قبل GCN است.
معماری RDNA بهبودهای دیگری نیز نسبت به آنچه گفته شد، با خود به همراه دارد. در مجموع معماری جدید در مقایسه با GCN چابکتر، موثرتر، کم مصرفتر و با کدهای گیمینگ سازگارتر است. روی کاغذ، خروجی نهایی افزایش توان محاسباتی و پهنای باند معماری RDNA نسبت به GCN افزایش نرخ فریم در محیطهای بازی خواهد بود.
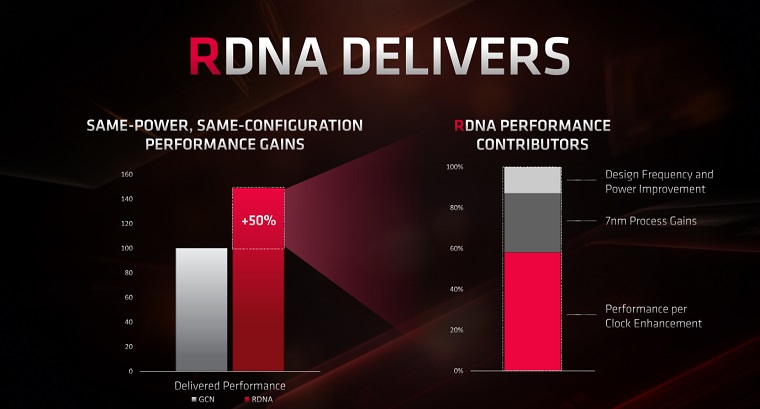
اگر بخواهیم نگاهی آماری به میزان برتری RDNA در مقایسه با GCN داشته باشیم، شرکت سازنده مدعی است که در سرعت کلاک یکسان معماری جدید ۲۵ درصد سطح عملکرد بهتری ارائه میکند. با این وجود با درنظرگرفتن فناوری ساخت تراشهی ۷ نانومتری Navi و امکان افزایش بیشتر سرعت کلاک نسبت به تراشههای Vega، معماری RDNA در یک مبنای قیاسی CU به CU تا ۵۰ درصد سریعتر از GCN است. بنا به ادعای AMD بهرهوری توانی (سطح عملکرد به ازای هر وات توان مصرفی) تراشهی گرافیکی Navi 10 تا ۵۰ درصد بیشتر از GCN است.
مروری بر کارتهای گرافیک مبتنی بر Navi 10
شرکت AMD در کارت گرافیک RX 5700 XT تمام توان محاسباتی پردازندهی گرافیکی Navi 10 را عملیاتی کرده و مقداری از منابع این تراشه را در کارت ضعیفتر RX 5700 غیرفعال کرده است. تراشهی Navi 10 مورد استفاده در این دو کارت سطح مقطعی معادل ۲۵۱ میلیمتر مربع داشته و با فناوری ساخت ۷ نانومتری TSMC ساخته میشود. AMD در این فضای کوچک ۱۰ میلیارد ترانزیستور به کار برده است.

تراشههای Navi نیز به مانند نسل سوم پردازندههای رایزن از استاندارد ارتباطی PCIe 4.0 پشتیبانی میکند. با پشتیبانی از این استاندارد پهنای باند اسلات محل نصب کارت ۲ برابر استاندارد PCIe 3 خواهد بود. چنین پهنای باندی برای بازیهای امروزی چندان قابل استفاده نیست؛ اما شاید به ابزار مناسبی در دست تولیدکنندگان محتوا برای اجرای رزولوشنهای بسیار بالا و پردازش مجموعههای سنگین داده تبدیل شود.
کارت گرافیک فیزیکی، PCB نسبتا بزرگی به طول ۱۰.۵ اینچ دارد که فضایی معادل دو اسلات را روی برد اشغال میکند. در این کار از یک فن دمنده برای خنککنندگی استفاده میشود که در شرایط ایدهآل خاموش است. دندانهی اضافی در لبهی کارت بیشتر جنبه زیبایی داشته و کارکنان AMD میگویند این دندانه یک "کنتور توانی" است. در میان درگاههای خروجی این دو کارت، درگاه USB نوع C دیده نمیشود؛ هرچند باتوجهبه نوع معماری امکان پشتیبانی از چنین درگاهی وجود دارد. پهنای باس کنترلر حافظه در هر دو کارت ۲۵۶ بیت است که با تراشههای حافظهی GDDR6 با سرعت 14GB/s کار میکند. پهنای باند حافظه در مجموع به ۴۴۸ گیگابایت بر ثانیه میرسد.
تفاوت کلیدی میان دو کارت RX 5700 XT و RX 5700 این است که کارت قویتر XT دارای ۴۰ واحد محاسباتی و ۲۵۶۰ پردازندهی جریانی است؛ درحالیکه مدل معمولیتر مجهز به ۳۶ واحد محاسباتی و ۲۳۰۴ پردازندهی جریانی است. البته سطوح مختلف سرعت کلاک در کارت RX 5700 در مقایسه با RX 5700 XT کمتر است و لذا سطح عملکرد محدودتری دارد.
یکی از اهداف اصلی معماری در تراشههای Navi دستیابی به سرعت کلاک بالاتری در مقایسه با پردازندههای گرافیکی Vega است. نگاهی به اعداد فرکانس ارائه شده توسط AMD چنین گزارهای را در کارتهای گرافیک جدید تأیید میکند. سرعت کلاک پایه و بوست کارت گرافیک RX 5700 XT به ترتیب ۱۶۰۵ و ۱۹۰۵ مگاهرتز است و این اعداد در کارت RX 5700 به ترتیب ۱۴۶۵ و ۱۷۲۵ مگاهرتز است.
AMD در کارتهای مبتنی بر پردازندههای گرافیکی Navi سرعت کلاک سومی را نیز با نام کلاک گیم معرفی کرده است. کلاک گیم تخمینی محافظه کارانه از حد فرکانسی است که میتوان از یک کارت Navi انتظار داشت. میتوان گفت این عدد سرعت کلاک مدنظر در بارگذاری معمولی (گیمینگ) است که انتظار دستیابی به آن وجود دارد. AMD میخواهد به کاربران مبتدی دیدی از سرعت کلاکی بدهد که در زمان اجرای گیم باید انتظار آن را داشته باشند. سرعت کلاک گیم در کارت RX 5700 XT معادل ۱۷۵۵ مگاهرتز و در مدل RX 5700 برابر با ۱۶۲۵ مگاهرتز است.

توان محاسباتی کارتهای گرافیک RX 5700 XT و RX 5700 به ترتیب ۹ و ۷.۵ ترافلاپس است. این اعداد با صرفنظر از مزایای معماری RDNA در مقایسه با GCN، بالاتر از کارت RX 590 بوده، اما در سطحی پایینتر از کارتهای RX Vega 64 یا RX Vega 56 قرار دارد. توان طراحی حرارتی مدل RX 5700 XT معادل ۲۲۵ وات و توان طراحی حرارتی RX 5700 برابر با ۱۸۰ وات است. منطقی است که تصور کنیم انطباق و مشابهت بخشهایی از معماری جدید با معماری GCN باعث میشود که کارتهای گرافیک Navi همچنان توان مصرفی بیشتری نسبت به کارتهای انویدیا داشته باشند. توان مورد نیاز هر دو کارت با ترکیبی از کانکتورهای تغذیه ی ۸ پین و ۶ پین تأمین میشود.
AMD براساس آزمایشهایی که خود به عمل آورده مدعی است که RX 5700 XT در برخی عناوین گیم و بالاترین سطوح عملیاتی API کمی سریعتر از کارت RTX 2070 انویدیا عمل میکند. براساس نمودارهای به نمایش در آمده توسط شرکت سازنده، کارت RX 5700 XT در بازی Battlefield 5 در رزولوشن 1440p و با تنظیمات گرافیکی Ultra تا ۲۲ درصد سریعتر از RTX 2070 کار کرده و در بازی Shadow of the Tomb Raider در همان رزولوشن و بالاترین سطح تنظیمات گرافیکی با اختلاف ۳ درصد از کارت تورینگ باز میماند.

در سوی دیگر این آوردگاه AMD تصویری از نتایج آزمایش کارت RX 5700 در مقایسه با RTX 2060 ارائه کرده است. براساس این تصویر این کارت توانسته در تمامی عناوین (ازجمله عنوان Shadow of the Tomb Raider) و در رزولوشن 1440p کارت رقیب را از پیش رو بردارد.
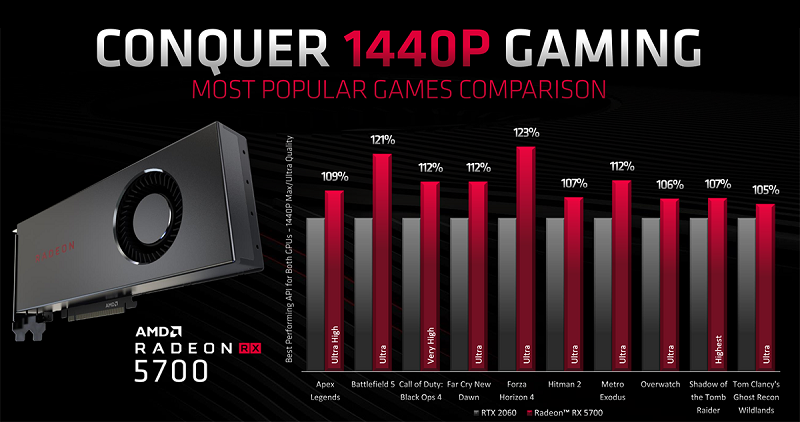
با نگاهی دقیقتر به سطح عملکرد این دو کارت گرافیک مبتنی بر Navi 10 مشاهده میشود که هر دوی آنها از کارت Vega 56 در سطح عملکرد پیشی گرفته و در حد و اندازه یک کارت Vega 64 ظاهر میشوند. هیچ کدام از این کارتها از نظر سطح عملکرد با کارت پرچمدار فعلی AMD با نام Radeon VII با قلب تپندهی Vega 20 و حافظههای گرافیکی بسیار سریع HBM2 برابری نمیکند. اما آنچه حائز اهمیت است این است که دستیابی به چنین سطح عملکردی با تراشهی فشردهتر و بهرهوری توانی بیشتر انجام پذیرفته است. پردازندههای گرافیکی Navi آمده است تا با ترکیب معماری تمیزتر و کاراتر، سلسله مراتب حافظهی کش هوشمندانهتر و فناوری ساخت فشردهتر AMD را به جایگاه شایستهی خود از نظر سطح عملکرد بازگرداند.
پردازندهی گرافیکی Navi 10 هیچگاه با هدف سرکوب پردازندههای پرچمدار Geforce طراحی نشده و حتی به گرد پای RTX 2080 Ti هم نمیرسد؛ اما در بازهی قیمتی ۲۵۰ تا ۴۰۰ یورو، کارتهای مبتنی بر این تراشه جانشین کارتهای فعلی Vega شده و تهدیدی برای میانردههای انویدیا به حساب میآید. البته نباید از یاد برد که انویدیا ردهی جدیدی از کارتهای گرافیک سری RTX را با نام Super در دست ساخت دارد که بهزودی وارد بازار سختافزار شده و جایگزین کارتهای فعلی RTX 2000 شده و سطح عملکرد تمامی اینکارتها را از میانرده تا پرچمدار ارتقا خواهد داد. در این صورت شاید غلبهی کارتهای Navi بر برخی میانردههای RTX 2000 در حال جایگزینی، چندان درخورتوجه نباشد. البته باید منتظر نتایج عملکرد تمامی این کارتها توسط بررسیگران و در جریان آزمایشهای مستقل ماند.
عرضهی هر دو کارت Navi 10 در تاریخ هفتم ژوئیه طی مراسمی رسمی در لس آنجلس آغاز خواهد شد. AMD برای کارت RX 5700 قیمتی معادل ۳۷۹ دلار در نظر گرفته و یک برچسب قیمت ۴۴۹ دلاری بر کارت قویتر RX 5700 XT کوبیده است. این شرکت همچنین خبر از عرضهی نسخهی 50th Anniversary کارت گرافیک RX 5700 XT داده است که در آن از آبکاری طلا در اطراف فن و روی قاب کارت استفاده شده است. این کارت با فرکانس های بالاتر ۱۶۸۰، ۱۸۳۰ و ۱۹۸۰ مگاهرتز و با قیمت ۴۹۹ دلار (۵۰ دلار گرانتر از مدل مرجع) در دسترس علاقمندان قرار خواهد گرفت.
.: Weblog Themes By Pichak :.
